Connected cars
Una soluzione per aggregare dati sviluppata in Java e AWS
Andrea è uno sviluppatore Java, appassionato di Wrestling e amante del Giappone. La soluzione di cui ci parlerà è pensata per il contesto automotive e permette a dati provenienti da diverse fonti di confluire in un unico punto. Il risultato è un’ottimizzazione dei costi e delle prestazioni in funzione delle tecnologie.
Introduzione
Negli ultimi anni è cambiato il modo di concepire e progettare le automobili. Questo cambiamento non arriva dall’addio ai diesel e dall’aumento esponenziale delle auto elettriche, ma dalla commercializzazione di modelli paragonabili a device su quattro ruote. [1]
Dalla definizione di automobile [2] si è arrivati al concetto di smart car, una macchina che ha sia le caratteristiche della self driving car sia quelle della connected car. [3]
Una connected car è un veicolo che, oltre ad avere accesso a internet, dispone di sensori e può inviare e ricevere segnali, percependo la realtà circostante e interagendo con altri veicoli o entità. [4]
Le connected cars sono equipaggiate da sistemi informatici che gestiscono numerosi dati relativi all’utilizzo delle automobili e alle abitudini di guida dei conducenti. L’elaborazione di questi dati da parte delle case produttrici può avere finalità statistiche sulle prestazioni di ogni modello venduto sul mercato o finalità commerciali in base alle abitudini di guida dei clienti.
Durante l’analisi e l’elaborazione degli stessi, da parte delle case produttrici, è possibile che si riscontrino problemi. I diversi modelli con cui sono progettati i sistemi informatici non sempre garantiscono l’uniformità delle informazioni recuperate.
Al fine di risolvere queste problematiche, i reparti IT dei diversi produttori devono riuscire a trovare delle soluzioni che consentano di uniformare le informazioni, non solo tra i vari sistemi informatici ma anche, e soprattutto, in funzione del tipo di analisi (statistica, commerciale, …) con cui dovranno essere elaborati dagli altri reparti aziendali (tecnico, commerciale).
Casi d’uso e architettura della soluzione
Nel corso di un meeting con un cliente, è emersa la necessità di trovare una soluzione univoca per la raccolta dei dati dai differenti sistemi informatici installati sulle connected cars in circolazione.
Ogni sistema di archiviazione dei dati aveva delle caratteristiche che dovevano essere tenute in considerazione, perché non coerenti tra i vari sistemi:
- range di informazioni raccolte
- formato dei dati
- tempistiche dei batch di raggruppamento dei dati (giornalieri o settimanali)
- meccanismi di archiviazione su file (storage in cloud o file system aziendali)
- formati e dimensioni dei file (xls, xlsx, csv, txt)
- accessibilità dell’archiviazione dati (permessi concessi ai diversi reparti)
Dopo alcune riunioni di confronto con tutti i reparti coinvolti, è stato definito uno stack architetturale che rispettasse i requisiti richiesti dall’azienda: un’architettura cloud e l’utilizzo di Java come linguaggio di programmazione.
I principali problemi da gestire sono risultati:
- l’elaborazione di file di dimensioni differenti (da pochi megabytes a pochi gigabytes), per cui è stato necessario considerare i limiti prestazionali del linguaggio Java a runtime
- la definizione di una formattazione dei dati
- la gestione dei dati dal loro recupero fino all’elaborazione finale
La soluzione proposta è stata quella di sfruttare alcuni servizi di cloud computing di Amazon Web Services (AWS) che hanno dei costi in funzione del loro utilizzo e consentono di scalare automaticamente le risorse necessarie per ogni processo coinvolto.
Nello specifico i servizi AWS scelti sono [5]:
- Amazon Simple Storage Service (Amazon S3) è un servizio di archiviazione (storage) di oggetti che offre scalabilità, disponibilità dei dati, sicurezza e prestazioni all’avanguardia nel settore.
- AWS Lambda consente di eseguire codice senza dover effettuare il provisioning (processo di preparazione e equipaggiamento di una rete per consentirle di fornire nuovi servizi ai propri utenti) né gestire server. Una volta caricato il codice, Lambda si prende carico delle azioni necessarie per eseguirlo e ricalibrarne le risorse con la massima disponibilità. Il codice può essere configurato in modo che sia attivato automaticamente da altri servizi AWS oppure richiamato direttamente da qualsiasi applicazione Web o mobile.
- Amazon Elasticsearch Service è un servizio completamente gestito che semplifica distribuzione, protezione ed esecuzione di Elasticsearch, un server di ricerca basato su Lucene, con capacità Full Text, con supporto ad architetture distribuite. Tutte le funzionalità sono nativamente esposte tramite interfaccia RESTful, mentre le informazioni sono gestite come documenti JSON.
- Amazon CloudWatch è un servizio di monitoraggio e osservabilità che fornisce dati e analisi concrete per monitorare le applicazioni, rispondere ai cambiamenti di prestazioni a livello di sistema, ottimizzare l’utilizzo delle risorse e ottenere una visualizzazione unificata dello stato di integrità operativa. CloudWatch raccoglie dati di monitoraggio e operativi sotto forma di log, parametri ed eventi, fornendo una visualizzazione unificata delle risorse AWS, sulle applicazioni e i servizi eseguiti in AWS e su server locali.
- Amazon Elastic Compute Cloud (Amazon EC2) è un servizio Web che fornisce capacità di elaborazione sicura e scalabile nel cloud. È concepito per rendere più semplice il cloud computing, erogazione di servizi offerti su richiesta da un fornitore a un cliente finale attraverso la rete internet.
Descrizione della soluzione
- La soluzione è suddivisa in due macro-attività:
recupero, formattazione e persistenza dei dati su Elasticsearch - aggregazione dei dati a disposizione dei reparti di analisi
La prima macro-attività è ulteriormente suddivisa in due soluzioni, considerando le dimensioni di ogni file da elaborare.
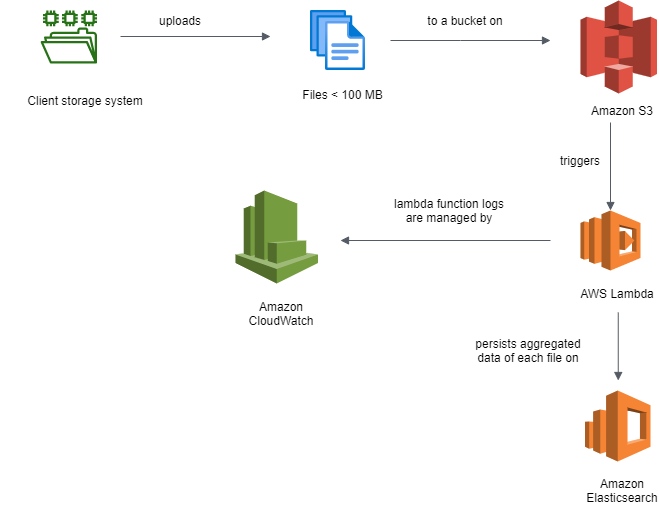
Per file fino a 100MB, la soluzione proposta è caricarli in un bucket (una cartella) di Amazon S3. Configurando correttamente una funzione Amazon lamba sviluppata in Java e associata a questo bucket, è possibile automatizzarne l’esecuzione al completamento del caricamento di ogni file nel bucket S3.
Il compito della funzione Java eseguita è leggere il contenuto del file e salvare su Elasticsearch esclusivamente le informazioni necessarie, già formattate nelle modalità richieste durante l’analisi.
È possibile monitorare l’andamento della sua esecuzione dai log generati automaticamente su Amazon CloudWatch. Il tempo complessivo di esecuzione di queste operazioni è considerato in funzione del limite di 15 minuti imposto su ogni funzione Amazon lamba.
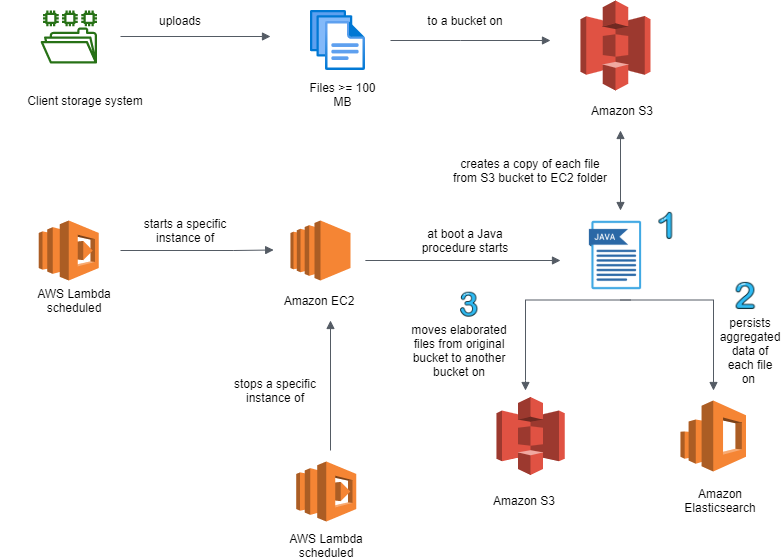
Per file superiori a 100MB, la soluzione trovata risulta più complessa. L’elaborazione di questi file supera i limiti delle funzioni Amazon lamba e può richiedere alcune ore per file con dimensioni dell’ordine dei gigabytes.
È necessario determinare che ogni file sia caricato in un determinato bucket (una cartella) di Amazon S3. Al completamento del suo caricamento, deve essere definita una nuova funzione AWS Lambda associata al bucket, il cui compito è quello di avviare una nuova istanza di Amazon EC2 (una macchina virtuale Linux preconfigurata).
All’avvio (boot) di questa istanza EC2, il file più recente presente nel bucket S3 è automaticamente copiato in una cartella temporanea di EC2 da una procedura Java. Il compito di questa procedura è leggere il contenuto del file e salvare su Elasticsearch esclusivamente le informazioni necessarie, già formattate nelle modalità richieste durante l’analisi.
Al termine dell’esecuzione il file su EC2 viene cancellato da EC2 per risparmiare risorse ed il file originale su S3 è spostato su un bucket differente. Per evitare che l’istanza di Amazon EC2 rimasse attiva, deve essere definita un’altra AWS Lambda schedulata col compito di spegnere l’istanza al termine dell’operazione di spostamento del file elaborato tra i bucket S3.
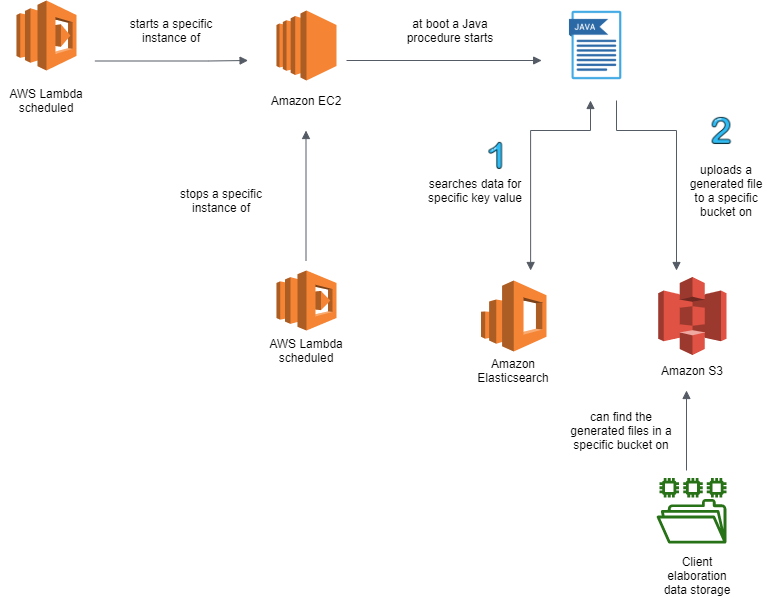
La seconda macro-attività consistite nel raggruppamento dei dati persistiti su Elasticsearch in funzione dell’insieme di valori determinati dall’analisi (es. modello di automobile e versione).
Una nuova funzione AWS Lambda ha il compito di avviare una nuova istanza di Amazon EC2 (una macchina virtuale Linux preconfigurata).
All’avvio (boot) di questa istanza EC2, una procedura Java legge automaticamente i dati, li elabora e produce un file contenente tutte le informazioni necessarie all’analisi. Questo file è accessibile ai reparti di analisi all’interno di un bucket di Amazon S3 dedicato.
Per evitare che l’istanza di Amazon EC2 rimanga attiva, deve essere definita un’altra AWS Lambda schedulata col compito di spegnere l’istanza al termine dell’operazione di spostamento del file elaborato tra i bucket S3.
La soluzione proposta, ottimizzata in rapporto a prestazioni e costi di gestione, può essere adattata a problematiche simili che utilizzino servizi cloud, anche differenti da quelli di Amazon, ed anche altri linguaggi di programmazione, considerando la disponibilità delle API di integrazione con i servizi cloud per il linguaggio scelto.
[1] La rivoluzione delle connected car – https://www.ilsole24ore.com/art/la-rivoluzione-connected-car-AEAo5LHE
[2] Automobile
[3] Smart car, tutto quello che c’è da sapere: cos’è, cosa può fare, come rendere intelligente un’auto – https://www.economyup.it/automotive/smart-car-tutto-quello-che-ce-da-sapere-cose-cosa-puo-fare-come-rendere-intelligente-unauto/
[4] Connected Car
[5] Servizi Amazon AWS – https://aws.amazon.com/