Smart Domains
Domain Layer Design, Event Sourcing & AI
Matteo è Senior Software Developer, aspirante Yogi e Runner. Nell’articolo di oggi descriverà come ingegnerizzare l’enterprise con l’intelligenza artificiale, portando l’esempio di un’azienda (import/export) che ha una flotta di mezzi da gestire.
Introduzione
Il trend crescente delle tecnologie 4.0 [1], fornisce una nuova modalità per trasformare dati prodotti da vecchi e nuovi sistemi informatici in nuovo valore aggiunto.
Grazie alla quantità, varietà e disponibilità di questi, specialmente la famiglia degli algoritmi di machine learning (ML) e data mining sono in grado di sfruttare al meglio e trasformare ogni dato prodotto in nuove informazioni utili. È certo che molte aziende che investiranno e sapranno sfruttare queste nuove tecnologie ne avranno un notevole beneficio nel prossimo futuro.
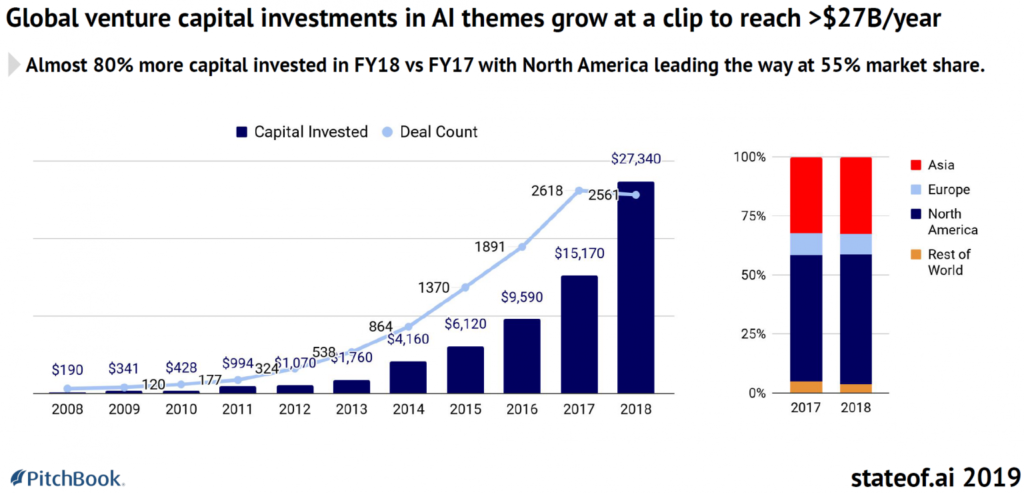
Mentre gli investimenti in IA crescono a buon ritmo, la richiesta di sviluppatori esperti nel campo non fa altrettanto. Infatti, la progressiva adozione di queste nuove tecnologie sta dividendo nettamente le categorie di sviluppatori creando nuove mansioni altamente specializzate.
Molte aziende scelgono infatti i grandi fornitori di servizi come Amazon e Google per soddisfare la crescente richiesta tecnologica relativa al campo dell’IA.
Ma è sempre la scelta più conveniente?
Penso sia ragionevole pensare che “non sempre” sia la risposta giusta.
Ci sono molti casi in cui lo sviluppo custom di una soluzione che sfrutta o addirittura incorpora l’IA può apportare grandi benefici, specialmente quando il settore tecnologico è situato in una “nicchia” di mercato.
Gli strumenti e librerie disponibili già realizzati non sempre sono adattabili ad ogni esigenza e spesso esiste una migliore implementazione più aderente alla necessità.
Credo che in tutti quei casi in cui l’intelligenza (artificiale) rappresenta uno degli aspetti basilari e principali di un prodotto software o una delle sue più utili peculiarità, lo sviluppo custom di queste debba essere preso in considerazione.
Ci sono scenari d’uso ove questo è già realtà da tempo, robot per la pulizia casalinga, robot operatori nelle catene di montaggio e molte altre applicazioni nel campo della logistica.
Ad ogni modo penso che nel prossimo futuro molti avranno la possibilità di aggiungere alle loro soluzioni l’intelligenza artificiale come parte stessa (by design) del proprio business.
Ma come e perché farlo?
L’orientamento agli eventi piuttosto che alle sole entità (quando possibile) è divenuto piuttosto diffuso ed è ideale per incorporare l’IA direttamente a livello di design.
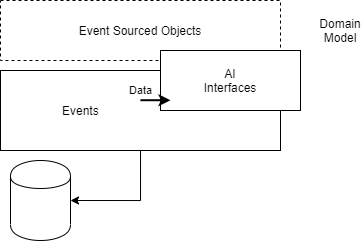
In questo articolo, cercherò di illustrare come approcciare un caso tipico utilizzando principalmente due tecnologie, Event Sourcing e Intelligenza artificiale a livello di modellazione degli oggetti del dominio [2].
Gli eventi che descrivono gli oggetti possono essere utilizzati per alimentare algoritmi intelligenti (classificatori) e di tipo statistico. Questi permettono così di aggiungere alcune proprietà, che chiameremo “smart”, agli oggetti stessi.
Un mezzo di trasporto ad esempio, oltre le proprietà che lo descrivono potrà esibire anche delle grandezze che esprimono una probabilità o una previsione.
È possibile far interagire queste proprietà direttamente con le regole di business: real-time senza una elaborazione a posteriori.
Questo colloca intelligenza e analisi dei dati direttamente nel dominio, contrariamente a ciò che molto spesso viene fatto oggi in molte implementazioni ove l’analisi tramite ML avviene in un secondo momento da file di log o metriche.
Tutti i concetti illustrati si basano su codice consultabile al seguente url: https://github.com/sandhaka/SmartDomainsCaseStudy
Un’azienda di import/export deve gestire una flotta di mezzi di trasporto. Nell’esempio è stata utilizzata una mappa semplificata per rendere più leggibile e comprensibile l’intero progetto.
Aggregati “Event sourced”
Capture all changes to an application state as a sequence of events.
[M. Fowler]
Se non lo conoscete già, Event Sourcing significa riferirsi a un oggetto non unicamente con il suo stato corrente, ma attraverso la serie di eventi verificatosi elaborati lungo tutta la sua vita [3]. Solo questi eventi saranno memorizzati, lo stato al momento desiderato sarà calcolato Runtime.
Come vale per un conto bancario, che non è una semplice tabella con l’importo del saldo all’ora di lettura corrente, così ogni camion della flotta può essere visto come un elenco di eventi relativi a tutte le sue partenze e arrivi.
Assieme a questi eventi, le metriche riportano tutti gli effetti del viaggio sul mezzo di trasporto e autista.
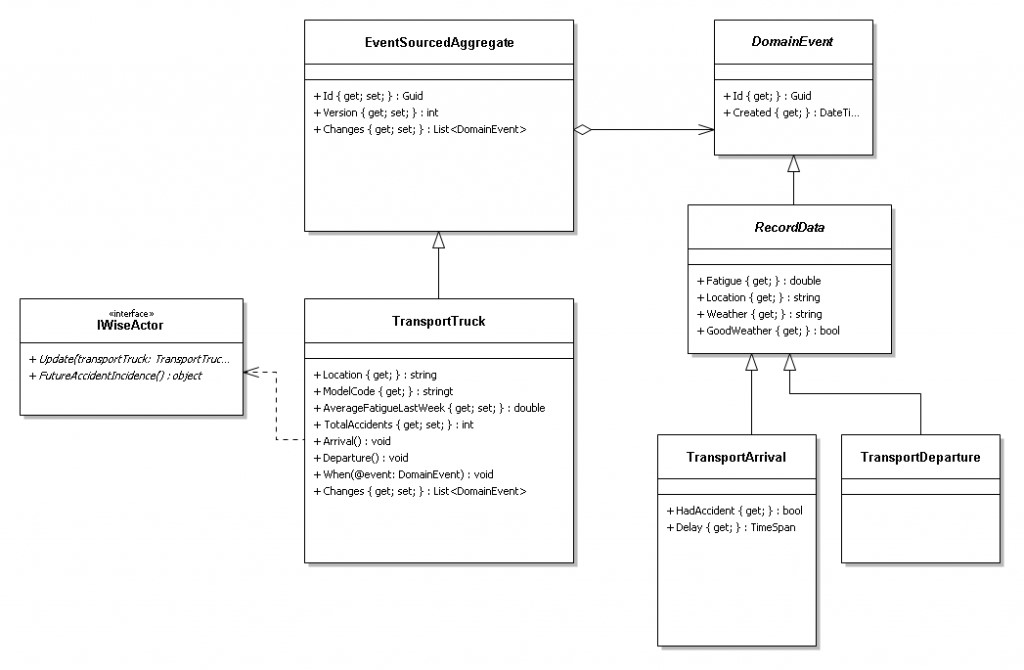
L’oggetto “truck” ha alcune proprietà come il codice modello, la posizione corrente e alcune metriche sullo stato corrente. Il valore decimale: AverageFatigueLastWeek descrive la mediana dello stress subito dal conducente nell’ultima settimana.
L’implementazione proposta sotto, elabora tutti gli eventi e calcola l’aggregato al momento di lettura.
Alla partenza non viene aggiornato nulla, perché le metriche vengono raccolte alla fine del viaggio.
L’aggregato può essere salvato o riletto come flusso di eventi (implementato nel codebase con un “in-memory” store).
Tutti gli eventi di dominio che rappresentano l’oggetto camion, poco sorprendentemente possono alimentare anche un algoritmo ML. Questo può imparare da tutte queste metriche circa il comportamento di ogni coppia camion-guidatore.
Un classificatore Naive Bayes stima la probabilità di avere un incidente durante il prossimo viaggio deducendolo appunto da questa sua storia.
Smart Properties
I classificatori Naive Bayes [4] sono una famiglia di semplici “classificatori probabilistici” basati sull’applicazione del teorema di Bayes.
L’implementazione dell’interfaccia IWiseActor del livello di dominio ci permette di sfruttare queste capacità e di prevedere un’incidenza probabilistica futura di un incidente in base alle attuali metriche di fatica del conducente, alle condizioni meteorologiche, alle statistiche storiche e così via.
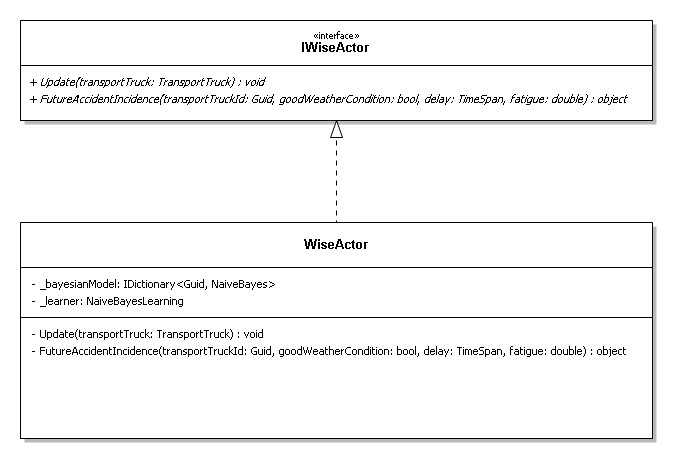
Il metodo Update permette di aggiungere o aggiornare il modello statistico del camion.
Mentre la variabile learner è un’implementazione di un classificatore “Naive Bayes” di terze parti.
In realtà, la base di codice proposta è già piuttosto corposa per essere usata come esempio, tuttavia anche se il dominio è solo un giocattolo, tutte le strutture necessarie per implementare una versione di aggregato Event sourcing sono molte.
Dopo la creazione della flotta (una raccolta di oggetti TransportTruck), una routine popola la lista degli eventi di ogni camion con alcuni dati precedentemente definiti. Queste metriche descrivono tutti i viaggi passati.
Ho usato xUnit per eseguire facilmente gli esempi, nel progetto di unit-test: TransportFleet.UseCase, il metodo ChooseTruckCandidateWith-LowerAccidentProbability fa il necessario e dimostra quanto sopra.
La parte interessante è la seguente, il metodo PredictAccident è incorporato nell’aggregato del dominio come un qualsiasi altro metodo di classe nonostante nasconda il necessario per ottenere i risultati ottenuti dal ML.
È possibile eseguire questo test dalla cartella del progetto:
Ottenendo l’output seguente:
Il modello del dominio è piuttosto semplificato e la previsione è banale usando solo alcune delle molte metriche ipotizzabili per una previsione di questo tipo.
Tuttavia, il codice è completo e utile per costruire casi d’uso più complessi.
Più AI, Constraint satisfaction
Il caso d’uso ML basato su Naive Bayes mostrato sopra è uno scenario molto comune.
Constraint satisfaction problem (CSP) è un altro ben noto modello matematico usato in intelligenza artificiale e ricerca operativa.
L’implementazione proposta è basata sul concetto di “backtracking”, in cui un algoritmo progressivamente abbandona dei valori candidati definiti a priori quando questi non sono in grado di soddisfare i vincoli del problema in questione.
Nell’esempio, dobbiamo organizzare tre viaggi per ogni giorno della settimana (dal lunedì al sabato) automaticamente utilizzando una flotta di sei camion.
Questo esempio è più elaborato del precedente. Prima viene creata una rappresentazione degli oggetti del dominio e poi viene elaborata direttamente da un generico algoritmo di risoluzione.
Il punto più interessante è la possibilità di inserire uno o più vincoli senza preoccuparsi troppo circa l’esistenza di una soluzione. L’algoritmo troverà quella che soddisfa la richiesta o una delle configurazioni più vicine possibili.
Per comprendere completamente il codice di cui sopra, probabilmente è necessario guardare l’implementazione del risolutore CSP utilizzata nell’esempio.
In ogni caso, anche questo è un altro buon candidato da includere direttamente a livello di business layer quando gli aggregati devono essere in grado di risolvere dei problemi di ottimizzazione combinatoria come quello qui descritto.
La pianificazione viene effettuata senza sovrapposizioni tra i giorni.
Se si vuole aggiungere un nuovo vincolo è molto semplice. Voglio assicurarmi che nessun camion faccia due viaggi consecutivi il lunedì e il martedì, per assurdo una regola di business stabilisce ad esempio che è troppo stressante.
Il risultato cambierà automaticamente in questo modo:
Si noti che nessun camion che viaggia il lunedì lo farà il martedì e viceversa.
È un sistema veramente utile per cambiare dinamicamente uno scenario complesso quando ho bisogno di ottimizzare l’assegnazione delle risorse in base a proprietà, vincoli, etc.
[1] Industry 4.0 – https://en.wikipedia.org/wiki/Fourth_Industrial_Revolution
[2] Domain-Driven Design (DDD) – https://dddcommunity.org/learning-ddd/what_is_ddd/
[3] Event Sourcing – https://www.martinfowler.com/eaaDev/EventSourcing.html
[4] Naive Bayes – https://en.wikipedia.org/wiki/Naive_Bayes_classifier
[5] Csp – https://en.wikipedia.org/wiki/Constraint_satisfaction_problem
Referenze
State Of Ai Report 2019
M.Fowler Web Site
Artificial Intelligence: A modern approach